Η Apple έχει εισαγάγει Slowfast-LLAVA-1.5, μια νέα οικογένεια βίντεο μεγάλων γλωσσών (Video-LLM) που έχει σχεδιαστεί για να κατανοεί αποτελεσματικά το βίντεο μακράς μορφής. Στο ερευνητικό της έγγραφο, η Apple εξηγεί ότι τα περισσότερα υπάρχοντα βίντεο LLMS αγωνίζονται με υψηλό υπολογιστικό κόστος και υπερβολική χρήση συμβόλων κατά την ανάλυση εκτεταμένου περιεχομένου βίντεο, το οποίο περιορίζει την ικανότητά τους να κλιμακώνονται. Το Slowfast-LLAVA-1.5 αντιμετωπίζει αυτό με την εισαγωγή ενός αποτελεσματικού πλαισίου που μειώνει τον αριθμό των μαρκών που απαιτείται για να αντιπροσωπεύει το βίντεο διατηρώντας παράλληλα την ακρίβεια.
Η απόδοση του διακριτικού είναι κρίσιμη επειδή κάθε πλαίσιο σε ένα βίντεο πρέπει να μετατραπεί σε μάρκες πριν το LLM μπορεί να το επεξεργαστεί. Με το βίντεο μακράς μορφής, ο αριθμός των μαρκών γρήγορα καθίσταται ανεξέλεγκτη, αυξάνοντας το κόστος και επιβράδυνση της απόδοσης. Η προσέγγιση της Apple συμπιέζει δεδομένα βίντεο έτσι ώστε να χρησιμοποιούνται λιγότερα μάρκες χωρίς να χάσουν σημαντικό πλαίσιο. Συνδυάζοντας αυτό με μια αρχιτεκτονική διπλής διαδρομής, όπου ένα "αργό" μονοπάτι συλλαμβάνει μακροπρόθεσμα πρότυπα και μια "γρήγορη" οδό επικεντρώνεται σε βραχυπρόθεσμες λεπτομέρειες, το μοντέλο μπορεί να εξισορροπήσει την κατανόηση με την αποτελεσματικότητα. Αυτό του επιτρέπει να παρακολουθεί τόσο τις πρωταρχικές ιστορίες όσο και τις λεπτομέρειες σε εκτεταμένες ακολουθίες.
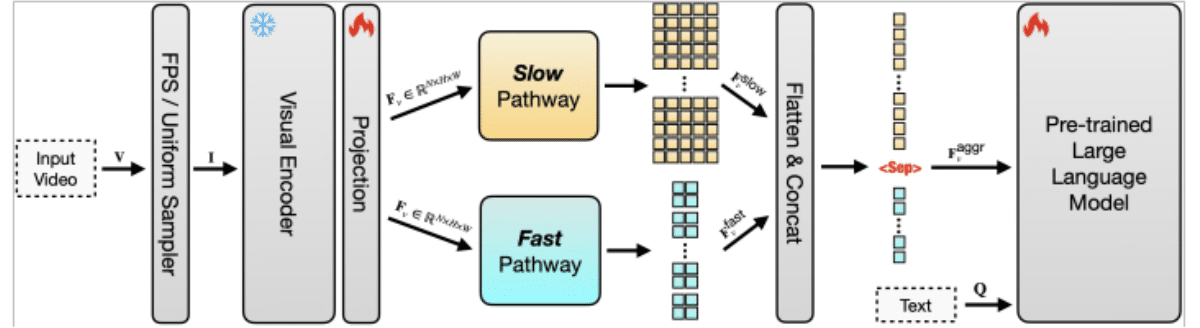
Το σύστημα είναι επίσης εξαιρετικά κλιμακωτό, πράγμα που σημαίνει ότι μπορεί να επεκταθεί για να χειριστεί πολύ μεγαλύτερα βίντεο και μεγαλύτερα σύνολα δεδομένων χωρίς συντριπτική υπολογιστική πόρους. Τα παραδοσιακά μοντέλα καθίστανται μη πρακτικά καθώς αυξάνεται το μήκος εισόδου, αλλά ο σχεδιασμός της Apple εξασφαλίζει ότι η κλιμάκωση από τα μικρά κλιπ σε πολυετές υλικό παραμένει εφικτή. Αυτό καθιστά το Slowfast-LLAVA-1.5 κατάλληλο για εργασίες, όπως η απάντηση στο βίντεο, η χρονική συλλογιστική, η περίληψη και η ανάκτηση περιεχομένου σε μακρά αρχεία βίντεο.
Στις δοκιμές αναφοράς, η Apple αναφέρει ότι το μοντέλο επιτυγχάνει ισχυρά αποτελέσματα σε σύνολα δεδομένων όπως το Video-MME και το LongvideObench, δείχνοντας τόσο βελτιωμένη αποτελεσματικότητα όσο και κατανόηση σε σύγκριση με προηγούμενες προσεγγίσεις. Η έρευνα εισάγει επίσης πολλαπλά μεγέθη μοντέλων, συμπεριλαμβανομένων των εκδόσεων παραμέτρων 1,5b, 7b και 13b, οι οποίες είναι ρυθμισμένες σε οδηγίες για να ακολουθήσουν τις προτροπές της φυσικής γλώσσας. Αυτό επιτρέπει στο σύστημα να παράγει λεπτομερείς απαντήσεις σχετικά με το σύνθετο περιεχόμενο βίντεο, καθιστώντας το εφαρμόσιμο για την εκπαιδευτική ανάλυση βίντεο, τη συνοπτική συνάντηση και τα εργαλεία προσβασιμότητας και τα εργαλεία προσβασιμότητας που δημιουργούν λεζάντες ή μεταγραφές που μπορούν να αναζητηθούν.
Η Apple υπογραμμίζει ότι ο αποδοτικός και κλιμακωμένος σχεδιασμός του Token δεν αφορά μόνο την ερευνητική καινοτομία αλλά την πρακτικότητα. Με τη μείωση των υπολογιστικών απαιτήσεων κατά την επέκταση της ικανότητας, το μοντέλο ανοίγει το δρόμο για την ενσωμάτωση της κατανόησης βίντεο μακράς μορφής σε προϊόντα πραγματικού κόσμου. Καθώς το βίντεο συνεχίζει να κυριαρχεί στην ψυχαγωγία, την εκπαίδευση και την επαγγελματική επικοινωνία, το Video LLM της Apple αντιπροσωπεύει ένα σημαντικό βήμα προς την κατεύθυνση της προχωρημένης πολυτροπικής AI τόσο χρήσιμου όσο και προσβάσιμου.
Δείτε το πλήρες χαρτίεδώ.
Προτεινόμενη ανάγνωση:Το Tiktok αγκαλιάζει περιεχόμενο μεγάλης μορφής με μεταφορτώσεις βίντεο 60 λεπτών